Case Studies
Our Work
Three recent engagements. What the situation was, what we did, and what changed. Client names are anonymised by default — available on request for qualified prospects.
CI/CD rebuild for a payments API
A Seed-stage fintech processing card payments had deployments that took 2–3 hours, required two engineers, and failed often enough that the team had developed an unspoken rule: no Friday deploys.
Production and staging were functionally different environments — database schema drifts, different environment variable configurations, a dependency that only existed in production. The immediate problem was the deployment time. The underlying problem was that nobody fully trusted the environments.
A PCI-DSS audit was also approaching. The existing infrastructure had no audit trail for infrastructure changes and no evidence of environment separation.
What we did
- GitHub Actions pipeline: build, test, deploy in separate jobs
- ArgoCD for GitOps deployments to EKS
- Terraform for environment parity (dev/staging/prod)
- AWS Secrets Manager for credentials
- CloudTrail audit logging for compliance evidence
- Runbook documentation + team walkthrough
Kubernetes migration for an HR platform
A B2B HR and workforce management SaaS with 35 engineers had outgrown its original deployment model. The application was a Rails monolith running on a single EC2 instance. Uptime averaged 97.1% — which sounds acceptable until you calculate that it meant roughly 220 hours of downtime per year.
The engineering team was spending an estimated 30% of its time managing or reacting to infrastructure problems. Onboarding new engineers took 1–2 days because the local development setup was undocumented and often broken.
What we did
- EKS cluster with four service namespaces
- Horizontal autoscaler configuration per service
- OpenSearch for centralised log aggregation
- Prometheus + Grafana monitoring stack
- Local dev environment via Docker Compose
- Developer onboarding guide: under 30 minutes
Hetzner VPS to AWS, with backups that actually work
A direct-to-consumer e-commerce brand selling across Europe was running its entire stack on a single Hetzner VPS. Two data loss incidents in the preceding year — once from an accidental file deletion, once from a failed server upgrade — had created pressure to do something. But nobody on the team had migrated infrastructure before.
There was no staging environment, no backup automation, and no monitoring. The first time anyone knew the site was slow was when a customer emailed.
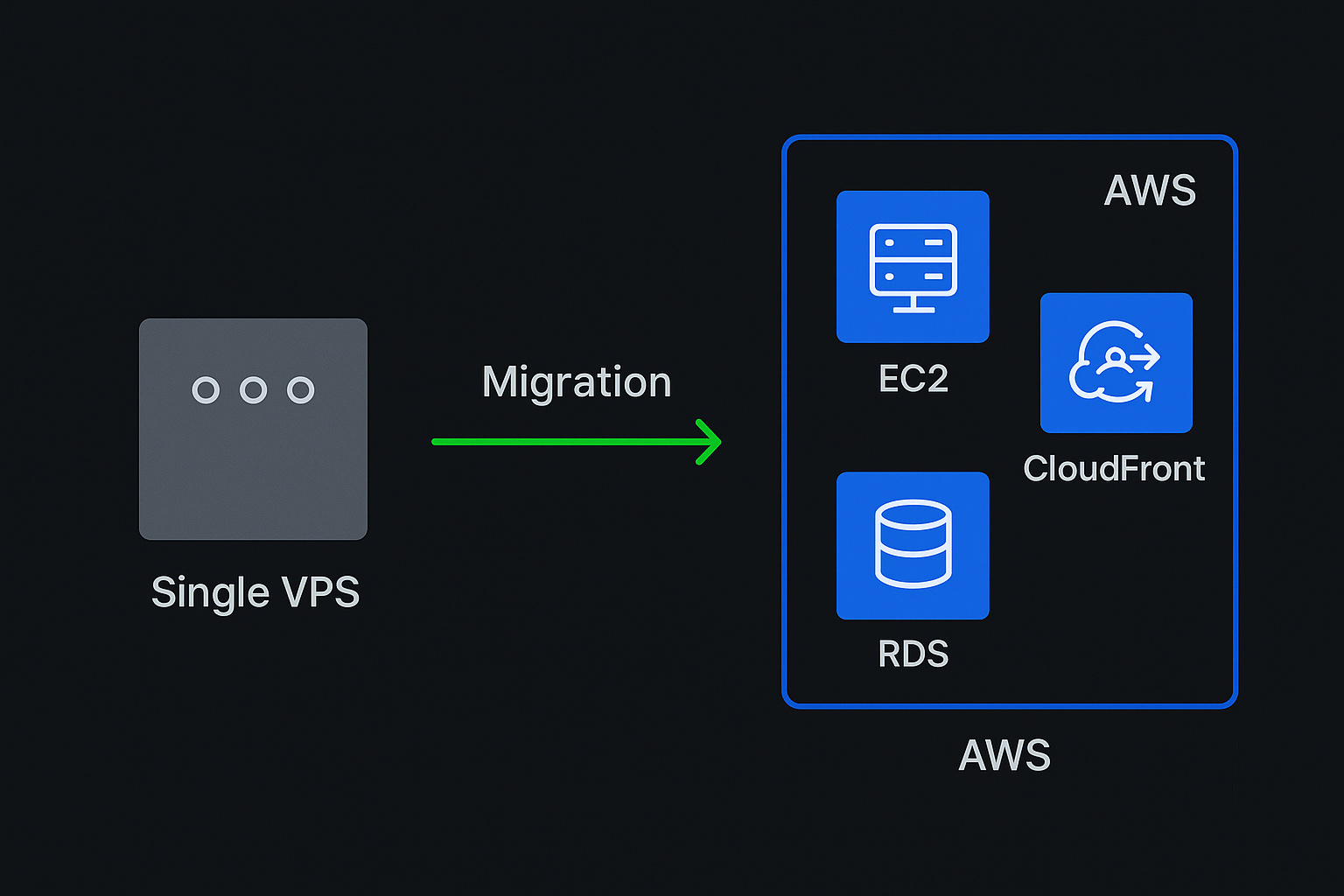
What we did
- AWS migration: EC2, RDS, CloudFront, WAF
- Automated daily backups to S3 with 30-day retention
- Staging environment (first time)
- CloudFront CDN for static assets
- Uptime monitoring + alerting
- Terraform for the full AWS setup
Work with us
Your situation is different. Good.
Every engagement starts from the actual state of the infrastructure. Tell us what you have and what needs to change.
Start the conversation