Your infrastructure,
running properly.
We work with engineering teams who have outgrown manual deployments, drifted environments, and the feeling that a single bad commit could bring down production.
What we do
Infrastructure work, not consulting decks
Six core capabilities, each applied to real infrastructure. Not scoped to death — scoped to what your team actually needs.
CI/CD Pipelines
Automated build, test and deploy pipelines. GitHub Actions, GitLab CI, ArgoCD. Code goes in, running software comes out.
Infrastructure as Code
Terraform or Pulumi to describe, version and reproduce your infrastructure. Environments that match. No more manual console changes.
Kubernetes & Containers
EKS, GKE or AKS — set up, configured, and handed over. Autoscaling, resource limits, namespaces, network policies done properly.
Cloud Migration
From bare metal, from a single VPS, from one cloud to another. We scope it, sequence it and run it — with a working staging environment before anything touches production.
Managed DevOps
Ongoing infrastructure ownership: monitoring, patching, incident response, capacity planning. Defined SLAs, real engineers on-call.
DevSecOps
Security scanning, secrets management, compliance controls built into the pipeline — not bolted on at the end when it's too late.
How it works
No discovery phase that lasts a month
We read your setup, ask specific questions, and propose a concrete plan. Most first calls are 45 minutes and end with a written scope.
How we workInfrastructure audit
We review what you have: architecture, tooling, bottlenecks. Written report with prioritised findings. No sales pitch at the end.
Scoped engagement
Fixed scope, fixed outcome, clear handover criteria. You know exactly what you're getting before we start.
Handover or ongoing
We hand over documented, working infrastructure — or stay on as your Managed DevOps partner. Your choice, made without pressure.
Our work
Three recent engagements
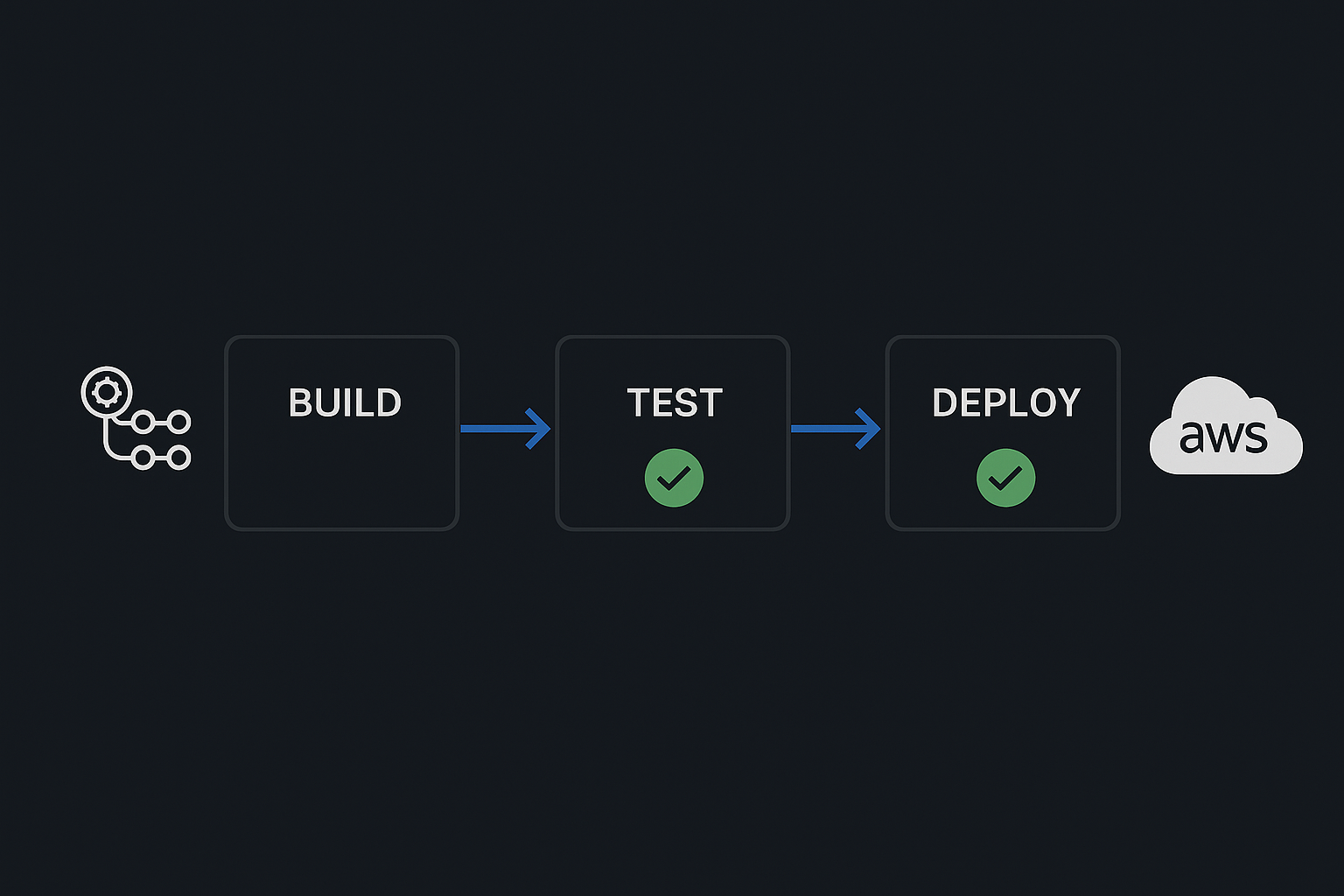
CI/CD rebuild for a payments API
Manual deploys taking 3 hours. One bad push taking down production. We rebuilt the pipeline, separated environments, and introduced a proper rollback strategy.
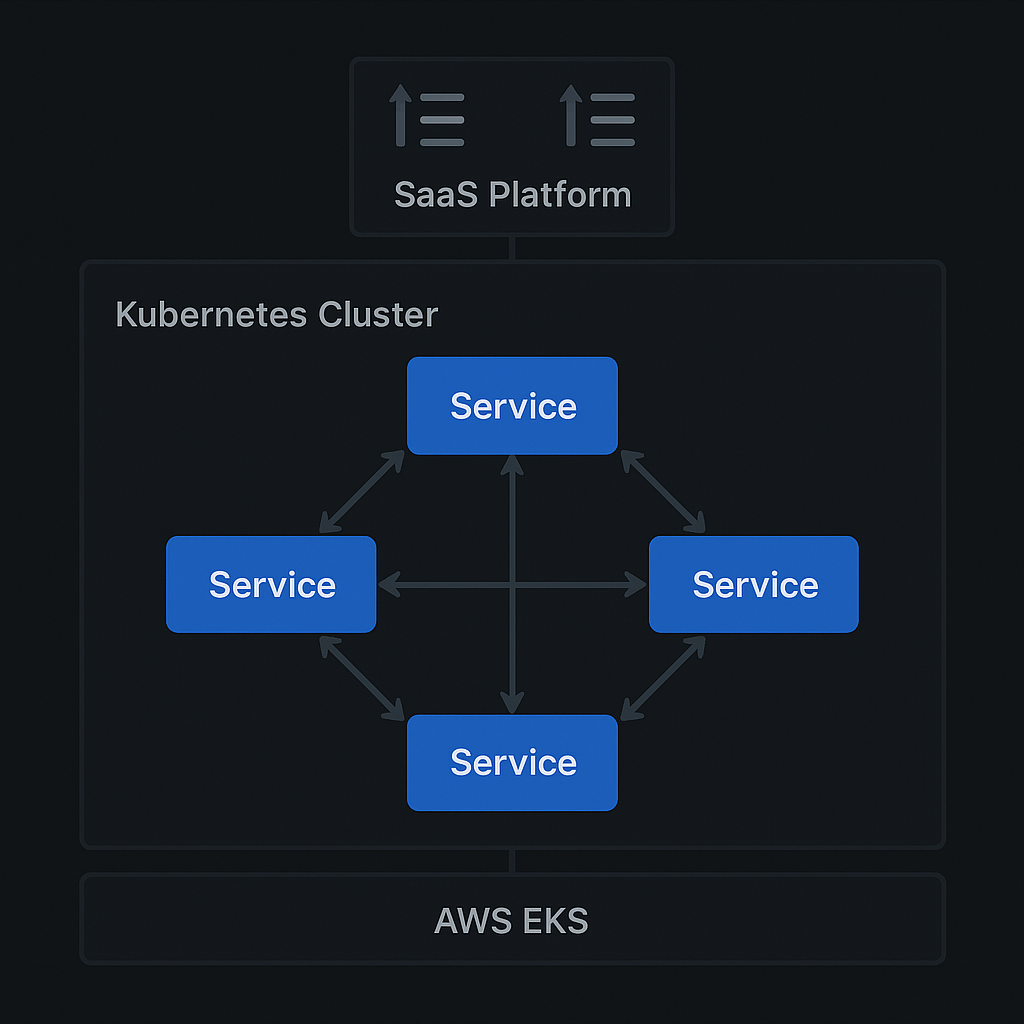
Kubernetes migration for an HR platform
A monolith on a single EC2 instance causing weekly outages. We moved to EKS, split the application into four services, and added autoscaling.
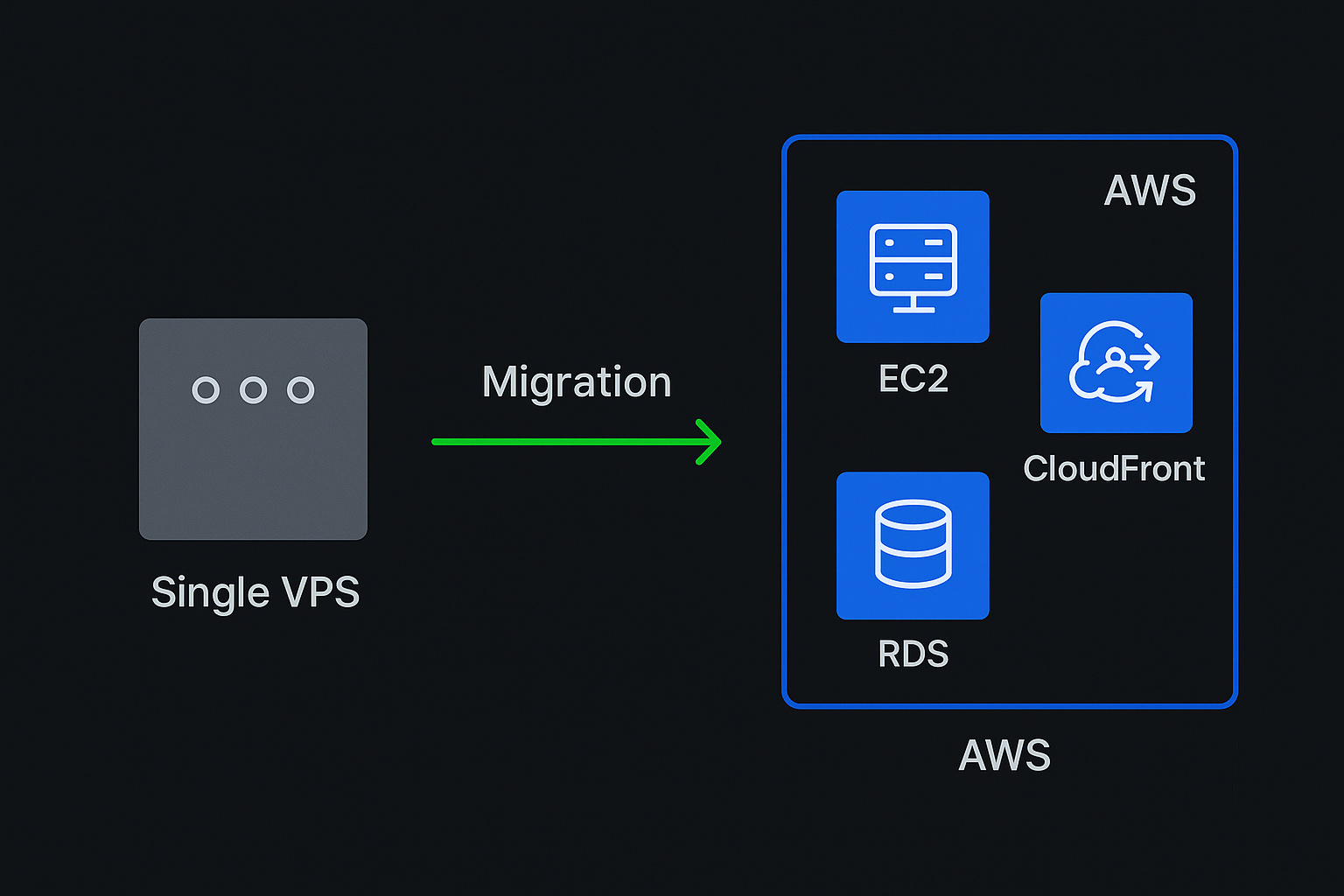
Hetzner VPS to AWS, with proper backups
Two data loss incidents in a year. No staging environment, no backups, no monitoring. We migrated to AWS and set it all up properly.
Tools we work with
What clients say
From the engineers who worked with us
We'd been meaning to fix our deployment process for two years. NodeFlow did it in three weeks, documented everything, and we actually understand what's running now. That last part surprised me most.
I was sceptical about outsourcing infrastructure to a small team. The difference with NodeFlow is that you're talking to the same person who's writing the Terraform. No account manager in between.
Infrastructure Notes
Practical writing on cloud and DevOps
All notes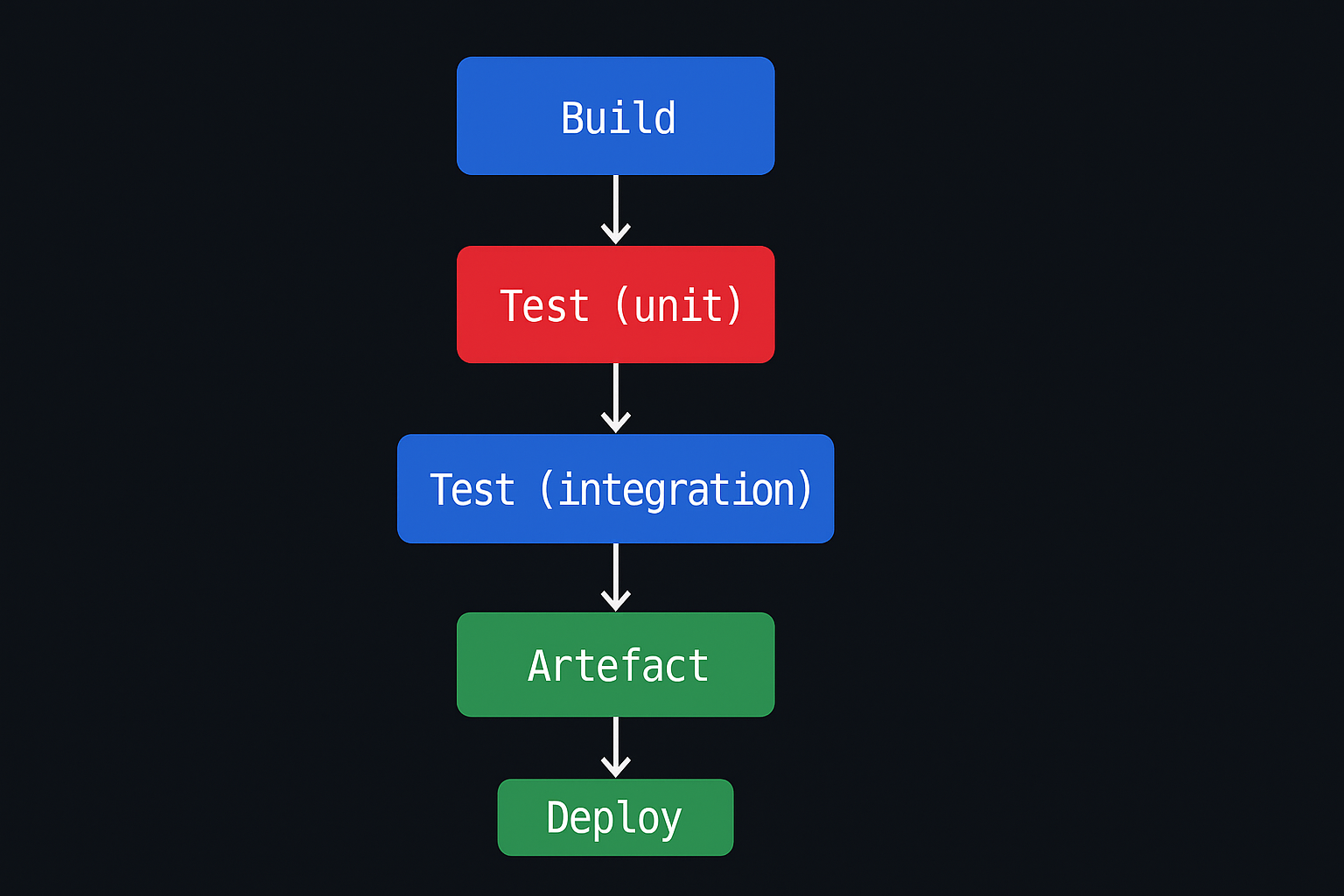
What a working CI/CD pipeline actually looks like
Most teams have some automation. Fewer have a pipeline where they can trace a commit to production in under 10 minutes with a single audit log.
Read note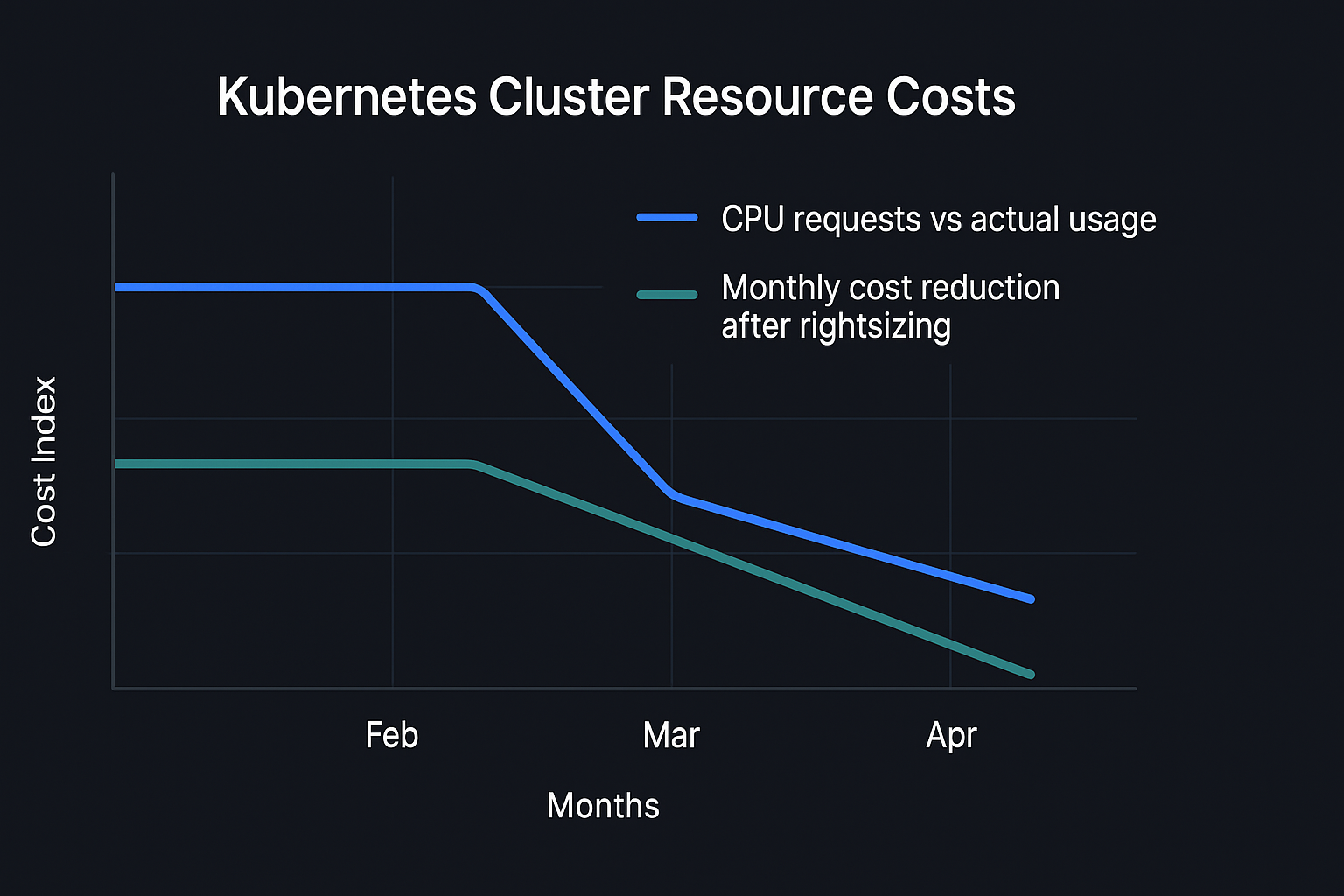
Reducing Kubernetes costs without reducing reliability
The most common source of overspend in Kubernetes clusters is not the workloads you know about — it's the ones nobody's looked at in six months.
Read note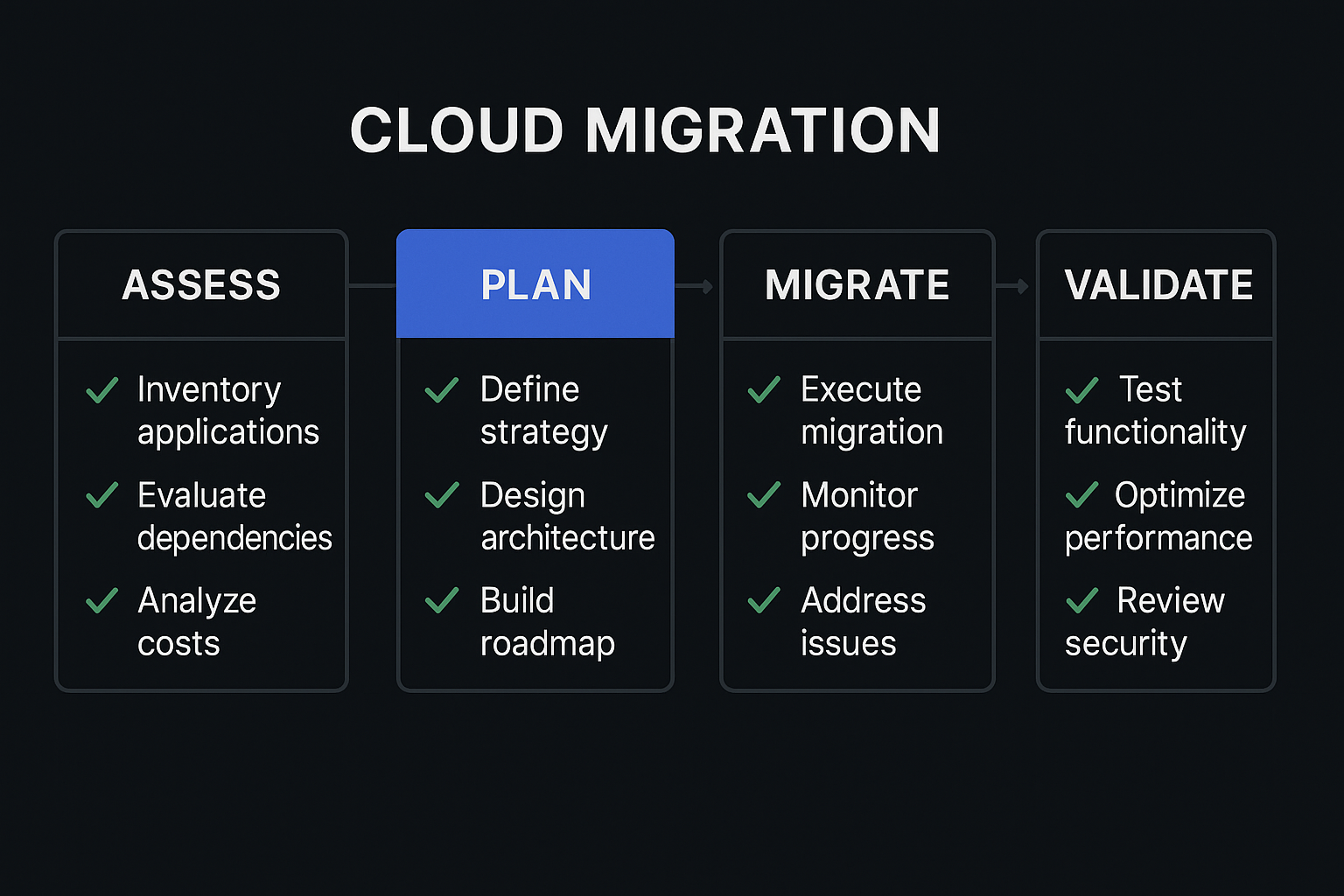
Cloud migration: the checklist we actually use
After several migrations, most of the surprises fall into predictable categories. Here is what we check before, during and after a migration.
Read noteGet started
Start with a conversation, not a proposal
Tell us what you're working with. We'll tell you honestly whether we're the right fit — and if not, point you in the right direction.
Talk to an engineer